Store-Optimizing Data Collection
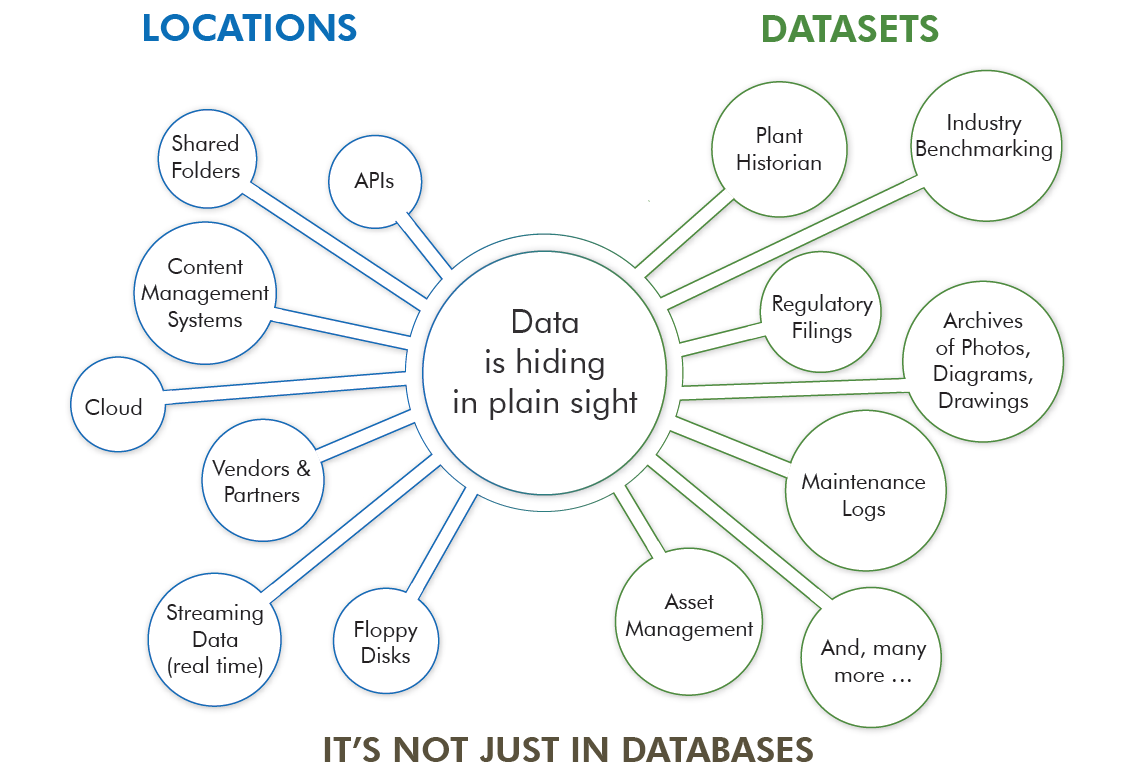
Many power companies are deploying new technology and sensors to capture entirely new sets of data that can help improve operational efficiency, safety, and reliability. The real payoff is the ability to combine this new information with existing data found throughout your company – to discover new insights and anticipate future conditions. To ensure you can use this new data for advanced analytics such as predictive or prescriptive modeling, you may need to revisit your data storage strategy.
Objective
In this brief, we introduce you to ways to think about data collection to ensure you capture and store relevant data that can be used more effectively for advanced analytics.
8 Questions to help you Optimize Data Collection
Quick Tips
- Scale data storage incrementally on an as-needed basis. Many low cast storage options such as cloud and virtual computing make it easier to increase capacity while minimizing upfront capital costs.
- Store data closest to the source For data collected from new technology such as sensors, initially evaluate and prepare data locally before moving it to longer term storage. This may save you from moving large quantities of data unnecessarily.
Review Data Collection Early & Often
As you work with new data sources from sensors, AMI, and smart systems it is important to check how data is being captured and stored early in the collection process. It helps you determine if you need to make adjustments to what data is being collected (types of data and various fields). You’ll want to identify early on if you need more or different information, and if you’re capturing the right data to support testing your hypotheses with analytics.
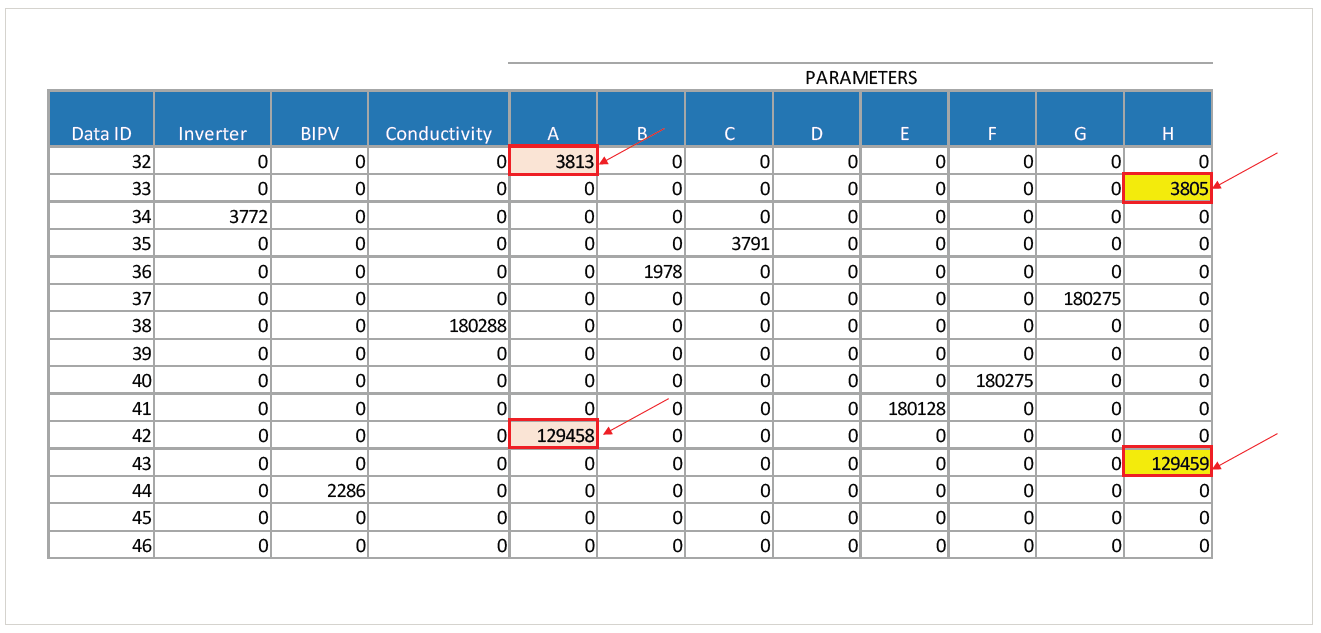
As an example, consider the preliminary data structure below, extracted from monitoring equipment. The Data IDs represent sensors at different locations throughout a plant, each of which typically collects different data. However, here we see two Data IDs capturing parameter A data, and two with parameter H data. This is unexpected. So you might question, is there more than one measurement location for each parameter? Or, is there an error in data collection and storage processes that records two readings?
New Uses for your Existing Data
To develop analyses using machine learning, you will likely be using data from operational systems that were originally collected for very different purposes. Your storage capacity needs may increase sharply to retain granular data that your systems currently either compress or discard. Not only will you save more data, but you will want to replicate data from operational systems so that it can be used in a separate analytics sandbox environment.
Mitigate Data Storage Roadblocks
 Quality:
Quality:
Evaluate early on the quality of information being collected by new technology, such as sensors or AMI, to help identify and fix issues.
Volume:
Measure performance and reliability related to storing time series data.
Variety:
Plan to store a wide variety of data types and formats including pdf files, video, audio, images, and social media posts.
Metadata:
Determine how missing information in metadata (descriptive information about datasets) will be captured as data is collected and moved to storage.
Conclusion
Start planning your data storage strategy based on what data structure you need to test your data science hypotheses. Your storage strategy needs to enable the creation of datasets to be used for advanced analytics.
Key Insights
- New data is being generated with advances in sensor technology and plant monitoring. Developing a preliminary data structure can help you better understand your data early in the store stage. You will likely identify new questions about the data that needs to be incorporated into your collection and storage plans.
- Optimize storage and system architecture to take advantage of time series data that offers a huge new opportunity for measuring operating changes over time. Time series analysis may help you detect previously unidentified cyclical patterns, correlations, and trends.
- Collect and store continuous data for a more complete picture of your operations. With a more well-established baseline for “normal” or “steady state” readings, you can detect slight drifts and indicators that operations are very slowly moving out of normal ranges. You can also connect abnormal readings to the plant’s broader environmental conditions taking place at the same time as the data collected.